
04: Scaling Laws & Capabilities: Which LLMs Perform How Well
-
Inverse Scaling: When bigger isn’t always better (Jun 2023, added 6/24/23)
Emergent Abilities of Large Language Models (Oct 2022, added 4/29/23)
ChatGPT’s One-year Anniversary: Are Open-Source Large Language Models Catching up?
LLMs achieve adult human performance on higher-order theory of mind tasks
Evaluating Language Model Context Windows: A “Working Memory” Test and Inference-time Correction
LLMs achieve adult human performance on higher-order theory of mind tasks
Evaluating Language Model Context Windows: A “Working Memory” Test and Inference-time Correction
Inverse Scaling: When Bigger Isn't Better (Jun 2023, added 6/24/23)
(link)
The paper collects various examples of negative scaling: when the LLM gets bigger (which typically means it gets better!), its performance on these tasks get worse. These tasks must reveal something deep about how LLMs work: somehow, some strengths that scale with the LLM’s size start to turn into weaknesses at increasing size. It’s actually quite intuitive: for example, the more pre-training an LLM has, the harder it is to get it to “forget” its pre-training. So a task that takes a famous saying (which the LLM will have seen many, many times in pre-training) and modifies it slightly might just get worse, the bigger the LLM is.
Here are the four task families they find which have negative scaling:
Strong Prior: Examples that cause LMs to prefer repeating memorized sequences over following in-context instructions.
Resisting Correction, where LMs must repeat sequences verbatim, despite the sequences containing small mistakes
Memo Trap, where LMs are prompted to write a phrase that starts like a famous quote but ends differently (example: “absence makes the hard go heavy” - the LLM doesn’t want to do that)
Redefine, where common symbols are redefined (state that π is redefined to 462, and ask the LLM for the first digit of pi) and correctly answering the question requires using the new definition
Prompt Injection, where the prompt contains an instruction to ignore further instructions contained in future input along with a further instruction.
Unwanted Imitation: Imitation of undesirable patterns in the training data
Modus Tollens, where LMs must infer that a claim “P” must be false, if “Q” is false and “If P then Q” is true
Distractor Task: Examples containing an easy “distractor” task that can be confused with the harder, real task
Pattern Match Suppression , where LMs are instructed to continue text in a way that violates a repetitive pattern
NeQA, where each question in a typical QA dataset has been negated by adding “not” after occurrences of the word “is”
Sig Figs, where LMs are instructed to round numbers to the correct number of significant figures, with the other multiple-choice option using decimal place Rounding
Into the Unknown, where LMs must choose which of two pieces of information would help answer a question
Spurious Few-Shot: Correctly-labeled but misleading few-shot demonstrations of the task
Hindsight Neglect, where LMs must assess if a bet is worthwhile based on its expected value (EV), given a prompt with examples where the outcomes of the bets match the EV, but the outcome in the final question does not
Repetitive Algebra, where many arithmetic examples in the prompt have the exact same answer as the final question, but the final few-shot example has a different answer
These tasks helped drive the discovery of U-shaped scaling (Wei et al., 2022a), where scaling trends on a task reverse beyond a certain scale. U-shaped scaling is preferable to inverse scaling since performance decreases initially but increases at large scales, as with several prize-winning tasks when evaluated on PaLM LMs.
Example for the Resisting Correction task, and the Modus Tollens task:
A lot more good examples in the paper. Across 10 tasks, here is the negative scaling for all LLMs: as the LLM compute goes up, task performance goes down. However, GPT-4 actually does quite well on many tasks, suggesting that instruction tuning helps.
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling (Apr 2023, added 5/6/23)
(link)
How do LLMs develop and evolve over the course of training, and based on how big they are? This paper does something clever and foundational: they take the exact same LLM at different sizes and training sizes and compare performance systematically as they ramp up both. This is what they try:
Then they test several questions:
How does bias in the training data influence learned behaviors? Turns out they’re able to replace (possibly biased) pronouns in the training data for another training run, and bias in the model’s output goes down successfully.
Does training order influence memorization? Note that memorization isn’t great because it means the model just spits back what it has learned, and isn’t really generalizing. But somewhat counterintuitively, it turns out training order mostly doesn’t matter! So you cannot simply place sequences that are undesirable to memorize at the beginning or end of training to successfully reduce the chance of memorization.
Do pretraining term frequencies influence task performance throughout training?
First, interesting finding from other papers (“Impact of pretraining term frequencies on few-shot reasoning”, 2022): They chart the performance of an arithmetic task given an input operand, and they concluded that accuracy tends to be higher for terms that are found more frequently in the training data compared to terms that are less frequent. The paper “Measuring causal effects of data statistics on language model’s factual predictions” shows that a model is better at answering factual questions the higher the frequency of salient entities in the training corpus.
Turns out the same effect is present here: the below chart shows the 12B parameter model (x-axis: number of relevant entity counts found in the training data, y-axis: accuracy on Trivia QA with highest point at 50%). The various lines are different model training checkpoints. So, the more you train, the better the accuracy (obviously); but also the more often some related entity shows up in the dataset, the more the model is able to answer a question related to it.

Chinchilla's Wild Implications (Jul 2022)
(link)
The underlying OpenAI paper derives the optimal performance scaling laws for LLMs. It has some very counter-intuitive insights.
Data, not size, is the currently active constraint on language modeling performance. Current returns to additional data are immense, and current returns to additional model size are miniscule; indeed, most recent landmark models are wastefully big.
If we can leverage enough data, there is no reason to train ~500B param models, much less 1T or larger models.
This is a problem because we don’t actually have enough input data in most expert domains.
Here is the performance equation they derive:
If you plug in the numbers for Gopher, 280B parameters, trained on 300B tokens: L = 0.052 + 0.251 + 1.69 = 1.993
The “finite model” term is tiny! Scale the model to infinity, and the most you can improve is by 0.052 reduction in loss. But add more data, and you could do a lot better.
Chinchilla is 70B parameters (1/4 of the Gopher size), trained on 1.4T tokens: L = 0.083 + 0.163 + 1.69 = 1.936
At least in terms of loss, Chinchilla doesn't just beat Gopher. It beats any model trained on Gopher's data, no matter how big. To put this in context: until this paper, it was conventional to train all large LMs on roughly 300B tokens of data. (GPT-3 did it, and everyone else followed.) Insofar as we trust our equation, this entire line of research -- which includes GPT-3, LaMDA, Gopher, Jurassic, and MT-NLG -- could never have beaten Chinchilla, no matter how big the models got.
Great visualization of the efficient frontier of LLMs:

Emergent Abilities of Large Language Models (Oct 2022, added 4/29/23)
(link)
It is clear that certain LLM abilities quite suddenly emerge, once the model gets bigger than a certain threshold. We don’t really know how that works, but we do know it’s the case. This is a nifty paper that looks at when certain abilities of LLMs emerge: how big, which model? The summary table is below:
And here is a nice illustration as to how rapidly this happens. This shows the accuracy of two LLMs (Chinchilla and Gopher) on the massively multi-task language understanding benchmark - by (1) how much you train, (2) the model size, (3) the model’s perplexity on the WikiText103 corpus (this means how “perplexed” the model is when it re-sees its training corpus - lower is better because the model starts to be un-surprised/perplexed by seeing its training input again). Note that perplexity and training time are obviously very correlated here, but in the future there might be methodologies where you can un-link those two (like better retrieval from a corpus).

Finally, here is a great list of tasks where currently no model performs better than random: abstraction and reasoning corpus, authorship verification, checkmate in one, chinese remainder theorem, cifar10 classification, color, com2sense, cycled letters, discourse marker prediction, formal fallacies syllogisms negation, hhh alignment, kanji ascii, kannada, key value maps, language games, mathematical induction, minute mysteries qa, misconceptions russian, mnist ascii, multistep arithmetic, navigate, paragraph segmentation, play dialog same or different, presuppositions as nli, program synthesis, python programming challenge, real or fake text, roots optimization and games, salient translation error detection, self awareness, semantic parsing in context sparc, semantic parsing spider, simple text editing, sudoku, symbol interpretation, talkdown, tense, text navigation game, topical chat, tracking shuffled objects, twenty questions, web of lies, which wiki edit, winowhy, word problems on sets and graphs
What’s also weird is that emergence is still also dependent on the particular model: PaLM 62B shows emergence on many BIG-Bench tasks for which GPT-3 175B and LaMDA 137B do not, even though PaLM 62B has fewer model parameter and less training FLOPs. (Those tasks are: anachronisms, ascii word recognition, conceptual combinations, cryptonite, disambiguation qa, emoji movie, goal step wikihow, gre reading comprehension, linguistics puzzles, logic grid puzzle, metaphor boolean, metaphor understanding, odd one out, parsinlu qa).
LLMs and computation complexity (Apr 2023, added 4/29/23)
(link)
The simple but profound insight here is: LLMs do not have any internal state beyond a single token generation pass. Meaning, at any given point in time, the entire complexity of the problem it is trying to solve needs to “fit” into the LLM. We don’t know how to estimate that complexity, and the blog post actually does not do it correctly (the first comment on the post points that out and the author hasn’t had a good response yet). But one basic idea of the post is important: chain-of-thought prompting has (probably) little to do with “smart prompting” - it simply creates internal state for the LLM. Meaning, if it’s allowed to “take notes”, then those tokens can get fed back into its next output generation, and that means it has a better way to keep track of its own calculations - because between the generation of two separate tokens, there is no internal state that carries over from run to run. (An LLM doesn’t change its weights when it runs inference.)
PaLM 2 Technical Report (May 2023, added 5/11/23)
(link)
This is the Google technical report on their newest LLM, PaLM 2. Very interesting data points in here on scale laws for LLM. Various interesting insights:
Data and model size should be scaled roughly 1:1 to achieve the best performance for a given amount of training compute (as opposed to past trends, which scaled the model 3x faster than the dataset). Very interesting: PaLM 2 is significantly smaller than the largest PaLM model but uses more training compute, and it significantly outperforms the older model. There really exists a very different efficient frontier of model training than we used to think!
Larger models can handle more disparate non-English datasets without causing a drop in English language understanding performance.
We use a tuned mixture of different pre-training objectives in this model to train the model to understand different aspects of language, and not just a single causal or masked language modeling objective.
On scaling laws for LLMs:
Three parameters matter: (1) model size (# of parameters), (2) training data size (# of tokens), (3) training compute (# of FLOPs).
It turns out that the heuristic is: training FLOPs = 6ND to determine how many tokens to train each model for, with N = training tokens, D = model parameters. So: D and N should grow in equal proportions as the FLOPs budget increases.
They test that by training differently sized models with 4 training compute budgets (10^19, 10^20, 10^21, and 10^22 FLOPs). Then they check for each model how good its training loss is (the lower, the better). The lowest loss is achieved by the models that approximately follow the optimal model parameters (D) given the FLOPs. That’s what the table below shows: left column starts with the training compute, and for each compute, they test 4 model sizes with 4 training data sizes. It turns out that consistently, there is an optimal number of model parameters, and it’s not always the largest model! You can’t make the model larger than its training “appetite”.
Same in the chart below: see how the loss goes up again once the model becomes too big. Yes, the more you train (those are the 4 colors, each one stands for a training compute number), the lower the loss gets. And note how the highest loss in each new color is still below the lowest loss of the less-good color - so the model improves with more compute. But don’t make it bigger than necessary, for a fixed amount of compute! Then it gets worse again (loss goes up).
Also important: the training loss is not always the best indicator of actual model task performance. For example, the scaling results suggest that the optimal number of parameters for a model with 10^22 FLOPs is 10B. However, the 8.95B model, which shows the lowest loss (Table 1) and is closest to the optimal model, slightly underperforms the 14.7B model on downstream tasks. This suggests that while scaling laws can be used to achieve optimal training loss for a given quantity of FLOPs, this does not necessarily transfer to achieving optimal performance for a given task.
In terms of task performance:
How good is the model at reasoning? The table below shows various reasoning test datasets. PaLM 2 outperforms PaLM across all datasets and achieves results competitive with GPT-4.
Also, BB Hard (BIG-Bench Hard) is a subset of 23 BIG-Bench tasks where the best LLMs performed below the average human rater at the time of writing (e.g., tasks such as multistep_arithmetic_two, boolean_expressions). PaLM achieves the scores 52 (Direct) and 65 (Chain-of-thought), while PaLM 2 achieves 66 (Direct) and 78 (Chain-of-thought). They don't compare it to any other model.
On math, here are the results for various test datasets. Very good performance for PaLM 2, and the instruction-tuned version Flan-PaLM 2 is even better. (Minerva is a recent math-focused LLM.)
On coding, the model performs well, but the paper doesn’t show any benchmarks from other models. It gets around 50% accuracy on a difficult coding problem set.
The model is also incredibly good at translation, and in multilingual coding.
Finally, on memorization, some cool insights:
Neat to see what % of its trained content an LLM memorizes outright (you don’t want memorization, it’s dumb!): less than 1% for PaLM 2 (way better than the old model).
But also really interesting: not surprisingly, the more a model sees a particular sequence, the more likely it is to memorize it (this looks at 100-token sequences). Also, why is PaLM 2 worse than the old model here? The paper thinks it’s because PaLM 2 actually did a lot more de-duplication before training: so a 100-token sequence that repeats should be really rare, and if it does show up, it may actually be important enough to be memorized!
ChatGPT’s One-year Anniversary: Are Open-Source Large Language Models Catching up?
(Dec 2023, link)
Great overview paper of the current state of open-source LLMs. Open-source LLMs have reached GPT-3.5, but not GPT-4. Here is a useful classification of datasets (blue) and LLMs (yellow).

The following are general reasoning benchmarks: MT-Bench is designed to test multi-turn conversation and instruction-following abilities for writing, roleplay, information extraction, math, coding, knowledge. AlpacaEval tests the ability to follow general user instructions. Open LLM uses various sub-benchmarks on a variety of reasoning and general knowledge tasks. On Open LLM, even GPT-3.5 is still better than all open-source LLMs.
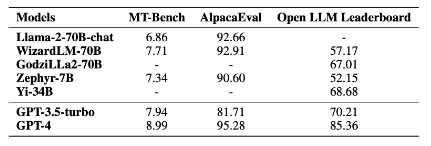
Here are agent benchmarks: they test LLMs’ ability to use tools, self-debug, follow natural language feedback, and explore their environment. GPT-4 is still way better.
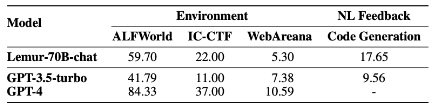
For problem-solving and coding benchmarks, some open-source LLMs are getting closer.

For long-context capabilities, Llama-2 seems to be approaching GPT-4 capabilities on long-context document summarization and Q&A.

LLMs achieve adult human performance on higher-order theory of mind tasks
(May 2024, link)
This is a remarkable paper with a surprising conclusion: LLMs are able to make at least 6 reasoning steps in “theory of mind” reasoning chains. That makes them at least as good as humans at this task. Theory of Mind (ToM) is the ability to infer and reason about the mental states of oneself and others. Human adults are generally able to make ToM inferences up to 5 orders of intentionality (e.g., I believe that you think that I imagine that you want me to believe). The paper generates 140 questions of that sort. The paper then surveys humans through the survey service Qualtrics on the internet. Below is an example question.

Here are the results. GPT-4 outperforms humans at order-6 theory of mind questions.

There is evidence that these two models were not susceptible to perturbations of the prompt. This is a novel dataset, so it is not in the LLM’s pre-training. So the results here present a potentially remarkable capability that LLMs seem to have acquired.
Evaluating Language Model Context Windows: A “Working Memory” Test and Inference-time Correction
(Jul 2024, link)
The paper runs a simple test on long-context LLMs: for a very long set of documents, generate some synthetic question and answer pairs on the documents, and then evaluate whether the LLM can answer them. The chart below shows that this is a much better test than the usual “needle in a haystack” (NIAH) test which just requires finding a simple factoid in a document: if the information that the question needs for a correct answer is in the middle of the set of documents (“depth” in document), then accuracy goes down a lot.

This is another great test result, on the left side: what happens when lots of documents are present that just have distracting content? Accuracy goes down by around 25%. The test on the right side reaffirms that the “lost in the middle” effect means that accuracy falls by 20-40% if the information is contained in the first 50% of the documents in the context window.

The paper then proposes a simple way to improve these results: run the question-answering task several times, but randomly mix up the order of documents in the long context window each time (“medoid voting”). The chart below shows what happens when you put the relevant information at position 25% in the document set, and then run medoid voting: you get an increase of 20%-points in accuracy.
