
09: Fine-tuning
-
RAG vs. Fine-tuning: Pipelines, Trade-offs, And A Case Study on Agriculture
Multitask Prompted Training Enables Zero-shot Task Generalization (Mar 2022)
Exploring the Benefits of Training Expert Language Models over Instruction Tuning (Feb 2023)
SUPER-NATURALINSTRUCTIONS: Generalization via Declarative Instructions on 1600+ NLP Tasks (Oct 2022)
One Embedder, Any Task: Instruction-Finetuned Text Embeddings (Dec 2022)
WizardLM: Empowering Large Language Models to Follow Complex Instructions (Apr 2023, added 4/29/23)
QLORA: Efficient Finetuning of Quantized LLMs (May 2023, added 5/25/23)
Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning (Mar 2023)
Parameter-efficient fine-tuning of large-scale pre-trained language models (Mar 2023)
LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention (Mar 2023)
Efficient Large Language Model training with LoRA and Hugging Face (Mar 2023)
Hugging Face: Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU (Mar 2023)
Accelerating LLaMA with Fabric: A Comprehensive Guide to Training and Fine-Tuning LLaMA (Apr 2023)
Could you train a ChatGPT-beating model for $85,000 and run it in a browser? (Mar 2023)
High-throughput Generative Inference of Large Language Models with a Single GPU (Mar 2023)
Building a conversational AI agent by finetuning an LLM (Jan 2023)
Specializing Smaller Language Models towards Multi-Step Reasoning (Mar 2023)
PMC-LLaMA: Further Finetuning LLaMA on Medical Papers (Apr 2023, added 5/7/23)
RAG vs. Fine-tuning: Pipelines, Trade-offs, And A Case Study on Agriculture
(Jan 2024, link)
The paper compares the performance of LLMs in answering agriculture questions for a base LLM, a fine-tuned LLM, and a retrieval-augmented generation LLM. An example question: “What is the best times to plant trees and shrubs in [Arkansas, Connecticut, Georgia]?”. Here is the pipeline the paper set up: start with an agriculture dataset, then generate Q&A data, then use that to a) fine-tune an LLM and b) set up RAG, then compare all of those.
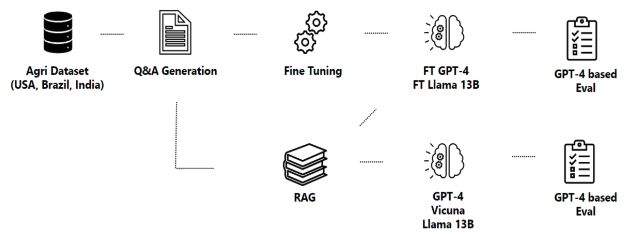
Step 1 is the information extraction from the agri dataset. The main problem here is information extraction from PDFs. Their goal is to not only to recover the content of each file, but also its structure - for example: sections and subsections, parsing the information presented in tables and diagrams, identifying cross-references within the document, and linking images with their caption and description. Various tools are available for this, but they are all deficient:
pdf2text: Able to recover the textual information, but markers representing the beginning of a section or subsection are lost within the retrieved data, hindering our ability to reason over the document structure. Captions of tables and figures are also lost in conversion but sometimes contain critical information for the understanding of the document.
pyPDF: Seems to have other limitations.
They decide to use GROBID, a machine learning library specifically tailored for extracting and processing data from scientific literature in PDF format. The use of GROBID, trained on a vast corpus of scientific articles, enables the recognition of a wide array of document elements and extraction of associated bibliographic data: it extracts a JSON description of the document’s content and structure.
They then use an LLM to generate 5-15 questions per document section.
Final setups:
They set up the following RAG pipeline:
Calculating embeddings for text chunks using sentence transformers
Retrieve relevant text chunks using FAISS with similarity_search_with_score
Use GPT-4 plus text snippets to generate the answer.
They set up the following fine-tuning pipeline:
They fine-tune Llama 2 and GPT-4
Here are the results. For RAG, retrieving more text chunks improves results:
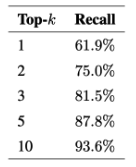
What’s also interesting is that the more content (base documents) you jam into the knowledge base, the worse recall gets, but it’s a relatively gradual decline:

This is the most important table, comparing fine-tuning vs. RAG. Really interesting, fine-tuning Llama2 doesn’t do anything for accuracy, only RAG improves it:

Correctness is here. RAG makes a big difference here, much more than fine-tuning.
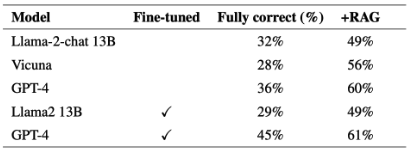
The following is a great table too: can GPT-4 learn new knowledge through fine-tuning? The answer is yes.

Direct Preference Optimization: Your Language Model is Secretly a Reward Model (Jun 2023, added 6/19/23)
(link)
Foundational theory paper which introduces a new algorithm for reinforcement learning. Reinforcement learning with human feedback (RLHF) is the stage in model training where we generate output from a pretrained LLM, and humans compare two versions of the same output and give that feedback to start moving the model towards better performance. This means that we first train a reward model on human preferences, and then the reward model is used to fine-tune the pretrained LLM.
This paper discovers that we don’t really need that in-between step of training a reward model. Their key insight is to leverage an analytical mapping from reward functions to optimal policies, which enables us to transform a loss function over reward functions into a loss function over policies. (Reward function: that reward model we train on human feedback; policy: the list of LLM outputs that humans marked up with their preferences.)
Again, from the “outside”, this means no difference in data collection for LLM training: you still first pretrain the LLM with lots of text, and then you create the human preference fine-tuning dataset. But concretely, we can now directly use the human feedback to fine-tune the LLM - no need for a reward model.
In terms of results, it turns out that in their tests, this Direct Preference Optimization algorithm (as opposed to Policy Preference Optimization, which is what we usually use in RLHF) is strictly better than PPO: it maximizes the reward in reinforcement learning while minimizing policy differences. This algorithm will probably soon be implemented in the various public libraries and over time replace RLHF in LLM fine-tuning pipelines.
Fine-tuning LLMs
LLMs are surprisingly good at tasks they weren’t explicitly trained for (like summarization, or sentiment analysis). An influential hypothesis is that large language models generalize to new tasks as a result of an implicit process of multitask learning (link): as a byproduct of learning to predict the next word, a language model is forced to learn from a mixture of implicit tasks included in their pretraining corpus. For example, by training on generic text from a web forum, a model might implicitly learn the format and structure of question answering.
LIMA: Less Is More for Alignment (May 2023, added 5/23/23)
(link)
This is a profoundly important paper: it shows that you can take Facebook’s open-source 65B-parameter Llama model, and fine-tune it with just 1,000 well-curated examples. Its performance gets exceptionally better: responses from the new model are either equivalent or strictly preferred to GPT-4 in 43% of cases; this statistic is as high as 58% when compared to Bard and 65% versus DaVinci003, which was trained with human feedback. It also outperforms another Llama-based model that was trained with 52K instructions. Analyzing LIMA responses on an absolute scale reveals that 88% meet the prompt requirements, and 50% are considered excellent.
The examples are as follows: 400x StackExchange (coders helping each other), 200x wikiHow, 150x Pushshift Reddit Dataset, 50x from Supernatural Instructions (a good dataset that describes stuff like “summarize this text”), 200x manually written prompts.
StackExchange and wikiHow are how you’d want a helpful AI agent to respond, and Reddit answers are humorous or trolling. The authors also write 200 instructions manually.
Interestingly, when writing the 200 manual examples, they answer most prompts with some acknowledgment of the question followed by the answer itself - this seems like it’s helping the model with chain-of-thought prompting (“let’s think step-by-step”).
Here is the model performance, really quite astounding for the fact that GPT-4 is probably at least a 500B-parameter model, and LIMA is a 65B-parameter model:
As usual (for instruction-tuning!), there is good generalization: for 50 examples outside of the set of training instructions (like “order pizza”), 45% of responses are rated as excellent, 35% as pass, 20% as fail.
Other insights:
Training data quality makes a huge difference: look at what happens if you don’t filter the training data from Stack Exchange.
Training data quantity almost makes no additional difference: here is the performance of a smaller, 7B-parameter model with different training inputs.
The following is absolutely insane, and really extremely counter-intuitive: in this chart, they test the model on multi-turn dialog, across 10 conversations. The basic LIMA model performs ok (left bar). But then they take 30 (in words: thirty) additional multi-turn dialog chains and add them to the 1,000 instruction-tuning pairs, to finetune another model. And those pitiful 30 additional dialog examples create a vastly better performance.
Exploring the Role of Explanations in Finetuning and Prompting for Reasoning Skills of Large Language Models (May 2023, added 5/23/23)
Three things matter at the core of LLMs: (1) their scale, (2) their fine-tuning, (3) their prompting. But, the age-old question: how much does each of those matter? Let’s find out! This paper tests this by creating 3x3x3 different versions of the OPT (Open Pretrained Transformer) model. Here is how they test:
For scale: 1.3B, 6.7B and 13B parameters.
For prompting: zero-shot (just ask), few shot (give a few examples and then ask), fewshot with explanation (give a few examples, and for each actually explain in natural language why this example is correct, and then ask).
For fine-tuning: no fine-tuning (OPT), fine-tuning without explanations (just give examples and fine-tune on those, OPT-R), fine-tuning with explanations (give examples and explain the best solution, OPT-RE). Here is a sample fine-tuning data point: “{task definition} / {In-Context Examples} / Input: {input} / Options: {options} / Output: The answer is {answer} because {explanation}”.
Here are the results across all 27 test combinations, across all tasks. So:
If you’re doing zero-shot, increasing model size or fine-tuning makes no difference. Very interesting! Even with tuned models, you still have to prompt smartly.
Not surprisingly, giving explanations - both in prompting and in fine-tuning - creates the biggest boost.
If you could just move one of these dimensions, then do fine-tuning with explanations: that makes the biggest relative difference.
But, overall, incorporating explanations really isn’t a massive impact. Below is variance (std) between model performance for fewshot (F) vs. fewshot with explanations (FE) prompting, and the average accuracy for those two methods. Yes, there is a consistent improvement from incorporating explanations. But it’s just not that big. But - the OPT base model isn’t a particularly good model, and that might be one issue here.
Multitask Prompted Training Enables Zero-shot Task Generalization (Mar 2022)
(link)
This paper tests the hypothesis: if I train a language model with several very distinct tasks (multitask learning), then is it able to generalize to tasks that were not explicitly included in its training set? The answer seems to be yes. This paper does the following:
It collects a lot of data sets that belong to different kinds of language tasks. The chart below shows all of those.
It then asked researchers to create prompts that accurately reflect the type of task. For example, for the “summarization” task, a prompt could be: “[text] Summarize this”, but also “Please write a succinct summary of what you read below: [text]”, or “I have one minute to understand the text below, please help! [text]”.
Because the input data sets already have the solution, you can do supervised learning on the language model.
It turns out that when you train a language model with this dataset, and you don’t include some of those areas above in the training (like sentence completion), then the model still gets good at that.
Here is this paper’s summary of the state of the art on training with the general idea: “multitask fine-tuning moderately sized LMs with instructions, also referred to as instruction tuning, enables zero-shot task generalization”.
Sanh et al. (2021); Wang et al. (2022a) have shown that scaling the number of training tasks, the number of prompts per task, and the size of the LM helps boost zero-shot task generalization performance => these papers are summarized here
Chung et al. (2022) include Chain-ofThought (Wei et al., 2022) tasks during instruction tuning, reaching state-of-the-art performance on zero-shot and few-shot settings with PaLM 540B
Lin et al. (2022) improve MT LMs by adapting MT LMs on subsets of the training data retrieved given a few unlabeled examples of the unseen task.
Ouyang et al. (2022) adapt MT LMs to align with human preferences through reinforcement learning.
Muennighoff et al. (2022) include multilingual tasks to show cross-lingual generalization capability.
Ye et al. (2022b) flip the instruction and label space to enhance generalization capability to novel unseen labels.
Asai et al. (2022b) utilize instruction tuning to construct a general-purpose retrieval system.
Similarly, Su et al. (2022) utilize instruction tuning to construct a general-purpose embedding model that can be used to perform different unseen tasks requiring text embeddings.
Exploring the Benefits of Training Expert Language Models over Instruction Tuning (Feb 2023)
(link)
The previous paper stated the idea that to train a LLM, it is smart to pick a whole bunch of different tasks (like text summarization vs. sentiment analysis), and to train one model on all of those tasks (multitask training - see above). The model then starts generalizing to other tasks that were not originally included in the training. In other words: scaling the number of training tasks, the number of prompts per task, and the size of the LM helps boost zero-shot task generalization performance for LLMs. Here is a nice illustration of how this usually works:
You have different categories of tasks (category level, such as text summarization vs. sentiment analysis). Those break down into different datasets that can be used for training (dataset level). Finally, you can formulate different prompts that make the language model do the same task, and try all of them.
This paper here, however, makes the observation that expert models can sometimes be better than entire multitask-trained models.
Take the same 296 tasks from the previous multitask learning paper. However, this time around, only train one model each for each task - so don’t train the entire model with all tasks. (In fact, the model actually freezes the backbone LLM, and just fine-tunes experts for each task - only the “adapters” get updated for each expert model.)
Then, they test all 296 tasks on all expert models. (They do that with 8 different datasets in this chart below.) Interestingly, it turns out that 7 expert models end up performing better on all tasks than the T0-3B multitask-trained model from the previous paper - even though they were only trained on one narrow task each. Somehow, those experts generalize phenomenally well.
These results imply that it is not actually the best approach to just increase the number of distinct tasks in multitask training - but rather, choosing the right expert vs. naively using a single multitask LLM is better.
Some reasons:
For multitask models, “negative task transfer” occurs: learning one new task makes the learning for a previously learned task worse. That doesn’t happen for expert models, because they just have to learn one task.
MT LLMs are subject to “catastrophic forgetting”: when getting trained with an additional task, they suddenly forget previous tasks, and thus require re-training on previous tasks.
We show that MT LMs show poor ability in performing composition of previously learned tasks given via concatenation of the corresponding instructions as a single compositional instruction. Instead, it is better to merge the two underlying expert models into a new expert.
So how does this paper train experts?
It trains experts for each task with the corresponding prompts and denote the resulting experts as Prompt Experts (PE).
For fine-tuning, they apply a parameter-efficient method of representing experts by training additional adapters while freezing the original parameters. It looks like they first train the whole LLM. Then they freeze the weights in the network after the self-attention layer, and they add an adapter feed-forward network before the self-attention layer. Only those weights can now still be trained.
No reason to read the original adapter fine-tuning paper, but here is how the idea of adapters works: the chart below on the right shows the usual transformer architecture - but two adapter layers were simply inserted. (Those layers are shown on the right.) Once the overall transformer is fully trained, you can now freeze all the transformer weights, the adapter layers are inserted, and only those adapter layer weights are now trained, on just the expert prompt and dataset. That’s the fine-tuning part.
Ok, now we have a fine-tuned LLM for each of the 296 expert tasks. (Again, each expert here actually isn’t just good for one particular task like sentiment analysis, it is also identified by the very particular prompt that is used to address it!) Now, how does the paper use experts?
First, the best expert for a particular task needs to be selected. The paper does that by using “dense retrieval” from an Expert Library. This is pretty clever and simple: to build the library, take S example training prompts from an expert’s training data (prompt + answer choice), then use a simple Sentence Transformer to calculate an embedding representation of the training instances. Now when you get a task, you can just turn that task into an embedding and search for semantically similar embeddings in the Expert Library, and you get back the expert whose prompt fits that embedding best.
Second, the paper also merges experts. This is a phenomenally simple approach: let’s say your fine-tuned LLM has 100 parameters. That’s a vector with 100 components. That vector has 20 components that belong to the adapter, and 80 that belong to the frozen original LLM. A merged expert parameter vector is simply calculated by averaging all the components of each experts’ 100-parameter vector. (Which of course means the frozen original LLM doesn’t get touched, only the adapter weights.)
The paper then tests on lots of tasks, and it shows that a single expert is able to outperform the previously trained multitask LLM (from the previous paper) on most tasks. Merging experts works even better.
SUPER-NATURALINSTRUCTIONS: Generalization via Declarative Instructions on 1600+ NLP Tasks (Oct 2022)
(link)
The paper collects a dataset of 1,616 NLP tasks and their natural language instructions, in 76 broad task types spanning 55 different languages.
It then trains a model that outperforms InstructGPT (which uses 16x more parameters). Each task is paired up with an instruction that consists of the task definition for mapping an input text to a task output and several examples for demonstrating the desired or undesired output. The model training is simply built by multitask training of the T5 model. (Unlike the previous paper, which does expert training!)
The 11B-parameter Tk-INSTRUCT can outperform the 175B-parameter InstructGPT model.
So this paper is simple: it turns out that the more distinct tasks as defined by prompt, negative examples, positive examples you jam into a model (here simply through multitask learning), the better it becomes.
Scaling Instruction-Finetuned Language Models (Dec 2022)
(link)
The paper explores instruction finetuning with a particular focus on (1) scaling the number of tasks, (2) scaling the model size, and (3) finetuning on chain-of-thought data. We find that instruction finetuning with the above aspects dramatically improves performance. Key insights:
Their model is called Flan-PaLM 540B, and it is derived by finetuning PaLM 540B.
The model instruction-finetuned on 1.8K tasks outperforms the original LLM by a large margin (+9.4% on average) and achieves state-of-the-art performance on several benchmarks.
Here is their dataset with 1,800 tasks that they’re finetuning on in total:
The experiments show that instruction finetuning does scale well with the number of tasks and the size of the model. This suggests that future research should scale up the number of tasks and the size of the model even further. Interestingly, going beyond using 282 tasks in finetuning doesn’t do much: possibly there isn’t much more for the model to learn in those other tasks. But also look at what scales here: you get around 15 points in improvement from finetuning in the smaller models, but increasing the model size gets you 40 points.
Our experiments show that whereas prior instruction finetuning methods that do not include chain-of-thought severely degrade performance on CoT evaluations, adding just nine CoT datasets into the finetuning mixture enables better performance on all evaluations. The table below shows the impact from including chain-of-thought (and a thing called self-consistency). Self-consistency is really simple: ask the model to create several chains-of-thought, and pick the path with the highest number of chains that lead to the same ultimate result.
In human rater evaluations, Flan-PaLM substantially outperforms PaLM on a challenging set of open-ended generation questions: human raters almost always think the Flan-PaLM answers are better.
How the model works for 57 tasks with model and human accuracy comparisons:
This is also interesting: the zero-shot accuracy is really impacted by finetuning with CoT. This means you can just ask the model to do something new, without even giving any examples, which require clever prompt engineering. (BBH is a set of tests.)
They finetune using the Adafactor optimizer.
One Embedder, Any Task: Instruction-Finetuned Text Embeddings (Dec 2022)
(link)
This paper looks at how to create more universally usable embeddings. Embeddings map an input text (or word) into a “meaning” vector. The problem is that if you’re trying to use a set of embeddings vectors for a very specific task, and then use the same set of embeddings vectors for a different task, the embeddings logic you used may not be useful in both task areas. For example, embeddings used for text sentiment analysis may not be that useful for information retrieval. This paper has a very simple idea: instead of creating an embedding for a particular text, concatenate an actual instruction of what to do with the text with the text itself - and do that with all the instructions that you’re likely going to use the embeddings for. In the example above, we have two instructions (“analyze the sentiment of this text” and “find the document that best answers this question”), and we simply concatenate those strings with the text in question, and then create two different embeddings. It turns out that creates embeddings that work much better for multitask purposes.
Below is an excellent visualization of that: this is the T-SNE visualization of embeddings space. If you just create embeddings for those sentences, then for the purpose of sentiment analysis, the light red dots aren’t particularly close, and the light green dots aren’t particularly far away - even though from a sentiment perspective that should be the case (light red are similar, light green are very different). But if you simply calculate embeddings that concatenate “compare the sentiment of this text” to each of these input strings, then suddenly the solid dots move into the right positions: solid red closer together, solid green farther apart. Giving this additional “meaning payload” suddenly helps the model “locate meaning” better in embeddings space. Simple stuff!
OPT-IML : Scaling Language Model Instruction Meta Learning through the Lens of Generalization (Jan 2023)
(link)
This paper compiles a large number of different training data sets for tasks. It uses them to do instruction-tuning on various famous LLMs. It finds some good tips to optimize the training, such as how to mix datasets.
WizardLM: Empowering Large Language Models to Follow Complex Instructions (Apr 2023, added 4/29/23)
(link)
Great paper in the tradition of self-instruct, out of which came Stanford Alpaca. The idea is that for a really good LLM, you need instruction-tuning, because instruction-tuning brings out a lot of emerging abilities from the LLM. Instruction-tuning just means you have lots of “instruction-input-output” pairs, like “summarize this text - text - summarized text”. The issue is that a) you have to create those instruction training datasets somehow, and b) if you do it manually they too often end up being pretty simplistic (because tired humans wrote them). So the paper’s idea is great and simple: use GPT-4 to “evolve” more complex instructions, called Evol-Instruct. It mass-produces open-domain instructions of various difficulty levels, that you can then use to fine-tune an LLM. Simple algorithm:
Start with an instruction, like “1 + 1 = ?”. Then apply either of the following:
In-depth Evolving = add constraints, deepening, concretizing, increase reasoning steps, and complicate input
In-breadth Evolving = mutation, i.e., generating a completely new instruction based on the given instruction
And for each new instruction, apply Elimination Evolving = instruction filter to screen out failed instructions
Great example here: start with the baseline instruction, and then iteratively re-write it using the above 6 methodologies (plus pruning out bad ones). All of this can be done through prompting GPT-4!
It turns out that this can create much more complex instruction-tuning datasets, here is the average difficulty level by instruction-tuning dataset (for 4 evolution runs of their own algorithm).
They then ask human raters to evaluate the instruction-tuning dataset. Across all difficulties, it’s more of a toss-up, but for difficulty >= 8, their methodology creates better instruction-tuning training data:
QLORA: Efficient Finetuning of Quantized LLMs (May 2023, added 5/25/23)
(link)
This is the new master paper to rule them all: QLora is a fine-tuning methodology for LLMs which reduces memory usage to the point where you can fine-tune a 65B-parameter LLM on a single 48GB GPU. (Previously, you needed 4x 48GB GPUs even for fine-tuning a 7B-model.) The basic trick is to quantize the weights of the LLM down to 4 bits, and then to use the frozen model to calculate Low-Rank Adapters (LoRA), plus other clever memory-saving tricks. Those adapters also have the advantage of having a lot fewer weights than the full LLM, meaning you can more easily share them. They use this to train the Guanaco family of models, and their performance is quite astounding:
So this is pretty incredible: even consumer GPUs (or even CPUs in a iPhone) can now fine-tune LLMs - and the results from using this fine-tuning methodology are basically the same as doing full fine-tuning.
Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning (Mar 2023)
(link)
Best overview of parameter efficient fine-tuning (PEFT): in the last 4 years, LLM size grew by 500x, but single-GPU RAM increased by only 10x. So model size currently scales two orders of magnitude faster than computational resources. At the same time, the limited context window of LLMs means you can’t really train on more than 100 or so input examples - so the need for fine-tuning persists.
Good datapoint: in practice, training a model requires 12-20x more GPU memory than the model weights
PEFT methods help, because they fine-tune only a subset of an LLM’s parameters. Here is the paper’s classification of methods:
Additive: Add some additional parameters to the model, and only train those.
Adapters: Train small fully-connected networks after transformer sub-layers
Soft prompts: Because LLMs have limited context windows, you can’t really give that many examples. So soft prompts fine-tune the model’s input embeddings using gradient descent. This changes the problem from finding prompts in a discrete space to a continuous optimization problem (of searching in embeddings space).
Selective: Don’t add additional parameters, but instead just train a subset of available LLM parameters.
Reparametrization-based methods: Those leverage low-rank representations to minimize the number of trainable parameters. Low-rank just means that a matrix gets instead viewed and updated in some lower-dimensional sub-space projection. (Very interesting: neural networks have low-dimensional representations! This has been widely explored in both empirical and theoretical analysis of deep learning.)
Low-Rank Adaptation (LoRA) is the most famous approach here: it employs a simple low-rank matrix decomposition to parametrize the weight update. It has been tested on models up to 175B parameters.
The paper then compares PEFT methods.
Five dimensions of comparison between PEFT methods: storage efficiency, memory efficiency, computation efficiency, accuracy, and inference overhead. Generally optimizing for one dimension doesn’t optimize for others.
The best PEFT methods have just 0.01-0.5% of the LLM’s trainable parameters and have been evaluated on model sizes > 20B (e.g., LoRA, Prompt tuning, Prefix tuning).
Explaining different methods:
Adapter: in each transformer block, send the input vector through a separate (and smaller) feed-forward network, then send both through the original transformer network.
Adamix: similar to Adapter, but instead of having one feed-forward adapter nets, have a couple of “experts” (each of which is a feed-forward net), and use those randomly. Kind of weird that that works.
Prompt tuning: prepend the model input with a trainable tensor (which is called the “soft prompt”). The soft prompt is discovered/trained through gradient descent. Soft prompts are incredibly parameter-efficient at the cost of inference overhead and more applicable to larger models
Prefix tuning: instead of adding a soft prompt to the model input, trainable parameters are prepended to the hidden states of all layers. (The same prefix is prepended to all transformer layers.)
LoRA: instead of changing all parameters in a weight matrix W during training, you can only change the parameters of two low-rank matrices Wa and Wb. All actual model parameters are frozen, only Wa and Wb are trainable. After training, they can be integrated into the original W by just adding Wa * Wb to the original matrix W. In transformers, LoRA is typically applied just to the key and value matrices in the self-attention modules (not to the FFNs).
When comparing the performance of these approaches: in practice, matching the performance of full fine-tuning remains a challenge. One of the reasons is high sensitivity to hyperparameters, with optimal hyperparameters often significantly deviating from those used in full fine-tuning due to the varying number of trainable parameters. The approaches that work best are LoRA and adapters.
Parameter-efficient fine-tuning of large-scale pre-trained language models (Mar 2023)
(link)
Fine-tuning an entire LLM is too operationally costly in almost all situations. The paper compares various methods to just fine-tune a smaller number of parameters in an LLM. Methods:
Adapter-based tuning: inject small-scale neural modules (adapters) to the transformer layers and only tune these adapters for model adaptation
Prompt-based tuning: wrap the original input with additional context.
Prefix-tuning prepends trainable continuous tokens (prefixes) to the input and hidden states of each transformer layer
Prompt-tuning is a more simplified strategy that only adds soft prompts to the input layer. Similar to prefix-tuning, the newly introduced prompts are not parameterized by the pre-trained model but an additional parameter matrix. And during training, the parameters of soft prompts are updated by gradient descent while the model parameters keep frozen.
The paper then compares all of these fine-tuning methods: vanilla fine-tuning (FT), prompt-tuning (PT), prefix-tuning (PF), LoRA (LR), adapter (AP). Here are the results. Turns out the various delta-tuning methods do almost as well as vanilla fine-tuning, but with a lot fewer parameters to update during fine-tuning.
LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention (Mar 2023)
(link)
This presents LLaMA-Adapter, a lightweight adaption method to efficiently fine-tune LLaMA into an instruction-following model.
Using 52K self-instruct demonstrations, LLaMA-Adapter only introduces 1.2M learnable parameters upon the frozen LLaMA 7B model, and costs less than one hour for fine-tuning on 8 A100 GPUs.
Specifically, we adopt a set of learnable adaption prompts, and prepend them to the input text tokens at higher transformer layers.
Then, a zero-init attention mechanism with zero gating is proposed, which adaptively injects the new instructional cues into LLaMA
Produces high-quality responses, comparable to Alpaca with fully fine-tuned 7B parameters (but of course much more cheaply trained!)
Our approach can be simply extended to multi-modal input, e.g., images, for image-conditioned LLaMA, which achieves superior reasoning capacity on ScienceQA.
Powerful: For different scenarios, it is flexible to insert their respective adapters and endow
LLaMA with different expert knowledge. Thus, it suffices to store a 1.2M adapter within each context, other than a complete copy of the 7B model.
By simply adding images tokens into adaption prompts, LLaMA-Adapter performs competitively on the ScienceQA benchmark.
Also, handles multimodality: previous PEFT methods are normally developed to address specific modalities, such as language, image, and audio. In contrast, LLaMA-Adapter can handle both language and multimodality fine-tuning with a unified manner, demonstrating superior generalization ability.
This is part of Parameter-Efficient Fine-Tuning (PEFT): include Prefix Tuning, Low-Rank Adaptation (LoRA), and the insertion of adaption layers in pre-trained LLMs.
Prefix Tuning appends a collection of prefixes to autoregressive language models, or alternatively, incorporates prefixes for both encoder and decoder components.
LoRA introduces trainable rank decomposition matrices into each layer
Adapters involves inserting lightweight modules into each layer of pre-trained models, which only updates the adapters and has been extended across numerous domains
Interesting list of vision models that get content into LLMs: LiT [54] utilizes pretrained image encoder to speed up CLIP [36] training. Frozen [43] fine-tunes an image encoder to transform visual tokens into LLM’s soft prompts. Similarly, CLIPCap [31] proposes a mapping network to connect the pre-trained image encoder with LLMs. Flamingo [1] inserts several cross-attention layers to inject visual knowledge into LLMs. BLIP2 [21] connects pre-trained image encoders and LLMs with a Q-Former. CLIP-Adapter [8], Tip-Adapter [55, 57] and PointCLIP [56,60] introduce customized adapters upon CLIP for 2D and 3D few-shot learning. To summary, these methods use mapping networks or cross-attention layers to connect vision and languages.
On implementation: the paper describes how it all works in more detail. The code is released publicly.
Efficient Large Language Model training with LoRA and Hugging Face (Mar 2023)
(link)
PEFT (Parameter Efficient Fine-tuning) is a new Hugging Face library that enables efficient adaptation of LLMS for new downstream tasks. Rather than fine-tuning an entire LLM and changing all weights, these methods typically modify way fewer parameters to get similar quality output. Currently includes:
LoRA: low-rank adaptation of LLMs)
Prefix tuning: creates specific soft prompts
P-tuning
Prompt tuning
The blog post describes the entire code needed to use the PEFT library to fine-tune Flan-T5 with a dataset of 16K conversations. Very helpful!
Clinical Camel: An Open-Source Expert-Level Medical Language Model with Dialogue-Based Knowledge Encoding
This paper has a really simple idea for better fine-tuning: it introduces Dialog-based Knowledge Encoding. The idea: if you want to do fine-tuning on a base LLM, and you have a big knowledge repository that you’d like to teach to the model, then first turn the knowledge texts into a synthetic dialog between a teacher and a student. That’s it - really simple, everything else stays the same. In this paper, they use this to train the 13B Llama model on a dataset consisting of 70K conversations from ShareGPT (website where users can share their ChatGPT conversations), 20K clinical articles and 10K MedQA multiple-choice questions.
Here are the results from the model on USMLE:
Empower Large Language Model to Perform Better on Industrial Domain-Specific Question Answering (May 2023, added 5/23/23)
(link)
Finally, someone is testing side-by-side whether a) prompting a huge LLM or b) fine-tuning a smaller LLM is better. This paper creates a dataset of Microsoft IT questions (based on the Microsoft Azure documentation), and then it checks which strategy works best. Here is the answer!
So:
“LLM” means they just ask the LLM the question with a prompt. “BM25” means they use retrieval: i.e., they search the Azure documentation and return the top-3 search hits, then they pass those into the LLM prompt. “Expert” means they fine-tune Llama-7B on their training Microsoft set, they prompt that model, and then they pass that model’s output into the LLM prompt. All of the rows in the above table are just various different ways to measure the model’s answer quality vs. the “golden” (best) answers.
So: it’s remarkable how a 7B fine-tuned model by itself really isn’t much of a competition. Even the LLM by itself, without any additional prompt data, can just answer the question better. But giving the LLM the extra knowledge from the fine-tuned model works best!
This is really interesting, it suggests you should use fine-tuned models side-by-side huge multi-purpose LLMs like GPT-4.
Hugging Face: Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU (Mar 2023)
(link)
To fine-tune an LLM with 10 GB parameters, you’d need 40 GB of RAM to fit it onto a single GPU. The library trl that this post discusses can reduce that.
Below is the so-called PPO training algorithm: it requires two models - in each training stage, you calculate the logits (output) of the old model to compare it to the new model. The idea is that we don’t want to lose too much of the old model’s functionality during fine-tuning.
What determines model size:
The precision of each model parameter: dtype. Most common are float32 (32-bit), float16, bfloat16. In float32, each 1B parameters cost 4 GB.
If you use an AdamW optimizer each parameter needs 8 bytes (for a 1B parameter model, the full AdamW optimizer of the model would require 8GB GPU memory)
How to parallelize:
Data parallelism: the same model is run on several machines, and each model instance is fed different data batches
Pipeline parallelism: the model is split layer-wise among several machines
Tensor parallelism: the tensor operations are split across multiple machines (e.g., matrix multiplications)
All of these require communication protocols between GPUs, and those aren’t easy to implement. There are also additional techniques like Adaptive activation checkpointing and fused kernels that become important here.
But how to fit all this onto a single machine? Two levers:
8-bit matrix multiplication: clever mathematical trick that chooses to do some calculations in int8 instead of float16 (“quantizing” the model). Reduces the size of a model by 4x.
Low rank adaptation: instead of training the entire model, freeze the weights and only create low rank versions of the query and value layers attention matrices.
PEFT (Parameter-Efficient Fine-Tuning): Hugging Face library to support fine-tuning adapter layers, integrated with the Accelerate library. How to use it:
Load the model in int8 precision. This can be performed by simply adding the flag load_in_8bit=True when calling the from_pretrained method. (Needs roughly 1GB GPU memory per 1B parameters)
Load adapters inside the model and make these adapters trainable. Leverages the peft library with a few lines of code.
For the PPO process, we still need the original model. Since adapters can be deactivated, we can use the same model to get the reference and active logits for PPO, without having to create two copies of the same model. (feature in peft library, which is the disable_adapters context manager)
Accelerating LLaMA with Fabric: A Comprehensive Guide to Training and Fine-Tuning LLaMA (Apr 2023)
(link)
Fabric is a new library by Lightning.AI which does two things: 1) Fully Sharded Data Parallelism (FSDP), 2) fine-tuning with LoRA (Low-Rank Adaptation of Large Language Models).
FSDP is a common technique that shards model parameters, gradients, and optimizer states across data parallel workers. Fabric provides a unified API that makes it easy to use FSDP. Fabric helps to automatically place the model and tensors on the correct devices, enabling distributed training, mixed precision, and the ability to select the number of devices to train on.
LoRA reduces the number of parameters in the LLM that need to get trained in fine-tuning and can thus run on lower GPU memory.
The Llama weights need to first get converted into Lit-Llama which is done by a script in a process described here.
StackLlama (Apr 2023)
Full RLHF training pipeline for Llama models.
When using 8bit quantization, you only need one byte for each weight, so 7B Llama is 7GB in memory.
When using LoRA adapters, a rule of thumb is to allocate ~1.2-1.4GB per billion parameters (depending on the batch size and sequence length) to fit the entire fine-tuning setup. As detailed in the attached blog post above, this enables fine-tuning larger models (up to 50-60B scale models on a NVIDIA A100 80GB) at low cost.
Reward Design With Language Models (Mar 2023)
(link)
The paper tests whether you can instruct an LLM to generate training examples for reinforcement training of an agent.
For the “ultimatum game”, one player gets $100 and proposes to share some of it with the other player. If the other player accepts, both get money, if not, both get nothing. It turns out that the LLM needs just one example and an explanation, and from then on acts to generate good training examples for another agent. Conclusion: LLMs are powerful because they can act on explanations. But this game is so simple that even an ML model would need just 10 examples to perform well.
For “deal or no deal”, a non-LLM ML model would need on the order of hundreds of more labeled examples in order to be comparably accurate to an LLM.
Could you train a ChatGPT-beating model for $85,000 and run it in a browser? (Mar 2023)
(link)
The Facebook Llama model still took a lot of training: 2,048 GPUs for 5 months. However, that was the cost to a) iterate and b) train all 4 versions of the model. Llama-7B is just 5% of that.
Llama/Alpaca at 4bit quantization is 3.9GB. There is also now a Stable Diffusion model that loads into the browser and can execute there, and it is 1.9GB.
Which GPU To Get For Deep Learning (Jan 2023)
(link)
Goes exhaustively through GPU types and how they work. Here is a good chart:
Cloud vs. dedicated desktop/server?
Rule-of-thumb: If you expect to do deep learning for longer than a year, it is cheaper to get a desktop GPU. Otherwise, cloud instances are preferable unless you have extensive cloud computing skills and want the benefits of scaling the number of GPUs up and down at will.
High-throughput Generative Inference of Large Language Models with a Single GPU (Mar 2023)
(link)
The basic idea here: for LLM tasks like classifying conversations in batch, inference latency doesn’t really matter, so this paper trades it off with high throughput. Previous attempts at optimization:
model compression to decrease total memory footprint
collaborative inference to amortize inference cost via decentralization
offloading to utilize memory from CPU and disk.
But: research in the first two directions often assume that the model fits into the GPU memory and thereby struggle to run 175B-scale models with a single commodity GPU. Offloading-based systems in the third category do not achieve acceptable throughput on a single GPU due to inefficient I/O scheduling and tensor placement.
So: To run an LLM with limited GPU memory, we can offload it to secondary storage and perform computation part-by-part by partially loading it.
On a 16GB NVIDIA T4 GPU, with 208 GB CPU RAM, their FlexGen system running, for example, OPT-175B achieves this:
The code is available here.
Vicuna-13B: Open-source Chatbot on Llama (Apr 2023)
(link)
Introduces Vicuna-13B, an open-source chatbot trained by fine-tuning LLaMA on user-shared conversations collected from ShareGPT. The authors say that their model performs better than Llama and Alpaca and get close to ChatGPT:
The model is fine-tuned on 70K conversations from ShareGPT.com, a website where users can share their ChatGPT conversations. Next, we enhanced the training scripts provided by Alpaca to better handle multi-round conversations and long sequences. The training was done with PyTorch FSDP on 8 A100 GPUs in one day. Other optimizations:
Memory Optimizations: To enable Vicuna’s understanding of long context, we expand the max context length from 512 in alpaca to 2048, which substantially increases GPU memory requirements. We tackle the memory pressure by utilizing gradient checkpointing and flash attention.
Multi-round conversations: We adjust the training loss to account for multi-round conversations and compute the fine-tuning loss solely on the chatbot’s output.
Cost Reduction via Spot Instance: The 40x larger dataset and 4x sequence length for training poses a considerable challenge in training expenses. We employ SkyPilot managed spot to reduce the cost by leveraging the cheaper spot instances with auto-recovery for preemptions and auto zone switch. This solution slashes costs for training the 7B model from $500 to around $140 and the 13B model from around $1K to $300.
Another interesting insight: their weights are released as a delta to the Llama weights - so you get the Llama weights and you simply add their weights to them.
Building a conversational AI agent by finetuning an LLM (Jan 2023)
(link)
They want to build a conversational agent for their company. Here is the process:
Pick the right LLM.
T5: Google model, transformer similar to GPT-3
FlanT5: T5 finetuned on 500 language tasks (multitask finetuning: see below). This makes it great at few-shot or zero-shot text tasks. But it can’t be finetuned on long articles because its attention architecture is quadratic in the input, like every normal transformer.
LongT5: T5-derived but especially designed to process large inputs. It uses a different attention mechanism called TGlobal (Transient Global) Attention Mechanism, which requires far less memory and allows LongT5 to excel at numerous tasks that other transformer architectures can’t handle due to memory shortage, such as scientific paper summarization or QA about Wikipedia articles. But LongT5’s available checkpoints weren’t fine-tuned on many tasks, so it didn’t perform very well on zero-shot scenarios.
Prepare the finetuning of the LLM
They first finetuned the model on much larger and more general datasets (SQuAD2.0 and CoQA). Training sequentially or combining both datasets made no difference.
They then finetuned it on their own examples, which they had to convert into prompt format: “{context} || <Q> {previous_question_2} <A> {previous_answer_2} <Q> {previous_question_1} <A> {previous_answer_1} <Q> {question} <A>”
Run the finetuning
Huggingface has good documentation on this. Some insights:
Using gradient accumulation, which lets you train on bigger batch sizes as the gradients get accumulated over several batches, and the optimization step is calculated after a certain number of them.
Using gradient checkpointing to reduce memory consumption by forgetting the activations during the forward pass and recomputing them on the backward pass of each training round.
Picking the right batch size to balance training speed and memory consumption.
Choosing optimizers that consume less memory, such as Adafactor (the optimizer used in the original T5 and LongT5 papers).
Tweaking parameters in the data loader, such as pinning the memory to the CPU and setting the right number of workers.
Distributing the training across both GPUs to leverage the computing power available.
Test the results
To assess its performance, we used the F1 Score by validating how many tokens appeared in common in both predictions and ground truth samples. We also used Exact match to see if the model was actually writing the same answer.
BloombergGPT (Mar 2023)
Bloomberg trained their own LLM - partly on generally available data, partly on their own financial data. A few conclusions:
On external (non-Bloomberg) financial tasks, it performs better than pure LLMs, but not by a lot. Also, those LLMs all perform much worse than GPT-4.
It performs really well on sentiment analysis:
On all the other typical LLM benchmarks, the model is fine, but not spectacular (and certainly worse than GPT-4)
Most interestingly, the model performs really well on Bloomberg-specific tasks:
Generating Bloomberg Query Language (because it knows stock tickers etc.)
Financial question answering with up-to-date data (because the model is trained on recent data).
The Economics of Large Language Models (Jan 2023)
(link)
Based on some simple calculations:
A model of the size of GPT-3 could be trained for just $1.4M in today’s public cloud
Specializing Smaller Language Models towards Multi-Step Reasoning (Mar 2023)
(link)
This paper shows that fine-tuning smaller LLMs (10B parameters and below) to more particular tasks makes them perform better at that task, and then lets you scale them up more linearly. The paper’s specific task is to make the model perform better on chain-of-thought math reasoning. The approach uses data generated from code-davinci-002 to tune the smaller FlanT5 models. It notes that using instruction-tuned base models increases performance overall.
Given a training question corpora, we use code-davinci-002 to generate 40 new CoT solutions then take the ones that lead to the correct answers as our training data. One solution consists of an answer and a chain of thought explaining the intermediate steps towards the answer.
Here are the results: the FlanT5 models all get quite a bit better at CoT math reasoning. But they all lose the ability to do well on generic tasks (in BigBench-Hard).
PMC-LLaMA: Further Finetuning LLaMA on Medical Papers (Apr 2023, added 5/7/23)
(link)
This is a somewhat weak paper overall, but it does run an interesting experiment: how much better does Llama get if you fine-tune it on medical literature, and then instruction-tune it further on medical Q&A? Interestingly, it really does not get that much better! The paper is confusing, but it seems to do two things, after starting with Llama 7B:
Run fine-tuning on 4.9M medical literature papers on PubMed (around 75B tokens).
After that, run instruction-tuning on the datasets PubMedQA and MedMCQA. (treat those as in-domain evaluation; they use the artificially generated PQA-A dataset of 211K question-answer pairs for training, and the labeled PQA-L of 1K pairs for testing)
Finally, they use USMLE as a test corpus to see how well it is doing. (treat that as out-of-domain evaluation; the train set contains 182K questions, the test set 4K questions)
The table below shows the accuracy in testing, depending on how the model got trained. The PMC-Llama model has fine-tuning on all PubMed papers. The PMC-Llama-7Bfull model has instruction-tuning on the PubMed and MedMCQA datasets, but it didn’t have previous fine-tuning on the PubMed papers.
So really, what do you see here?
The -7Bfull models get way better at answering these medical questions than the Llama-7B model. But that appears to be pretty useless as an insight, because the Llama-7B model wasn’t instruction-tuned at all, and so the model literally has problems with the format of answering a multiple-choice question. It is a powerful insight as to how much instruction-tuning matters.
The PMC-Llama-7Bfull vs. the Llama-7Bfull model really doesn’t get much better at all (and in one case worse). That’s really quite surprising, it suggests that the PubMed papers were part of the training corpus to begin with, and further fine-tuning made virtually no difference.
It’s interesting how much worse the PEFT fine-tuning is vs. the full fine-tuning. That’s kind of a bummer, since evidence seemed to suggest that PEFT is basically the same quality as full fine-tuning.
ChatGPT is still better at USMLE, but not much better at the other two (which were in-domain, however).
Summary Of Models Available For Fine-Tuning & In-house Execution
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Praesent ac leo posuere, cursus ex porta, accumsan tortor. Donec viverra fringilla leo, in suscipit diam tempus pulvinar. Nulla feugiat diam id ligula facilisis vulputate. Sed a egestas dui. Duis dapibus vitae lorem a ultrices. Duis luctus mi vitae est condimentum consequat et in arcu. Duis quis purus gravida, eleifend dolor nec, maximus lectus. Aenean eget nibh dui. Vestibulum a quam non leo venenatis ultrices non vel nulla. Integer nec convallis ex. Sed neque ex, ullamcorper ut feugiat id, consequat et neque. Quisque bibendum ligula neque, nec luctus odio tincidunt vitae. Phasellus iaculis urna arcu, non imperdiet turpis feugiat in.