
GPT-4 Turbo Benchmarking
By Lauren Pendo
Overview
Benchmarking model performance at Oscar
The pace of improvement of large language models (LLMs) has been relentless over the past year and a half, with new features and techniques introduced on a monthly basis. In order to rapidly assess performance for new models and model versions, we built a benchmarking data set and protocol composed of representative AI use cases in healthcare we can quickly run and re-run as needed.
Our benchmarking use cases:
Note-taking: Automated summaries of calls between customer service representatives and members that mirror the documentation agents submit after the call to describe what was discussed (in this case in a healthcare setting, replete with medical jargon).
Medical record parsing: Extraction of diagnosis information from medical records. For example, ICD-10s are a set of codes typically inputted by a physician into a patient’s chart and used to classify the patient’s disease state and symptoms for documentation and claims submission.
Clinical form structuring: Excerpting specific elements including diagnosis codes (ICD-10s) and procedure codes (CPTs) from, say, prior authorization (PA) forms.
We used GPT-4 to evaluate responses from our tested models and rate them on a scale from 1–4 for correctness, comprehensiveness, and readability. We also looked at the accuracy of extraction of ICD-10 codes and procedure codes. Note: Databricks also evaluated the use of LLMs to grade performance and found consistent results across models, meaning one model was not biased towards its own responses.
GPT-4 Turbo’s release
We set out to understand how the latest GPT-4 model, GPT-4 Turbo, performs on Oscar use cases compared to other models. We are excited by this new release and the power it unlocks!
Analysis
We tested GPT-4 Turbo on our standard Oscar benchmarking dataset, as well as medical records and calls that were previously too long for a single context window.
The following examples were previously too long to pass through GPT-4 due to the number of tokens. GPT-4 Turbo was able to extract the correct ICD-10 codes, however, it provided the wrong date of service for the correct ICD-10 code in one example, selecting a date of 1/15/1976. In another example it provided the same incorrect date for every sample, 12/03/20221. It appears GPT-4 Turbo was confused by the long context. Both the date chosen and the correct date occurred upwards of 80 times in the medical record (as they were both admission dates for the member). Given that the date does not appear directly next to the diagnoses, GPT-4 Turbo has a harder time reconciling the date it should choose. It appears to have selected a single date and used that for every diagnosis it found in the medical record. Note: We could try to improve the date extraction through more prompt engineering.
Interestingly, the ICD-10 code of G40909 is never explicitly mentioned in the medical record in question. Only the phrase `Seizure disorder (HCC/RAF) Unspecified epilepsy without mention of intractable epilepsy documented in this encounter` is mentioned, and GPT-4 Turbo made the association of this diagnosis to the correct ICD-10 code! Similarly, for the other example, K76.6 is never directly mentioned, but the diagnosis of “portal hypertension,” which corresponds to that ICD-10 code, is mentioned 12 times.
Long context examples:

Short Context examples
Below is an example where we can see the results generated by GPT4–32K and GPT-4 Turbo. With shorter samples, we did not see the same date issues in our extraction and saw similar results to GPT-4–32k.

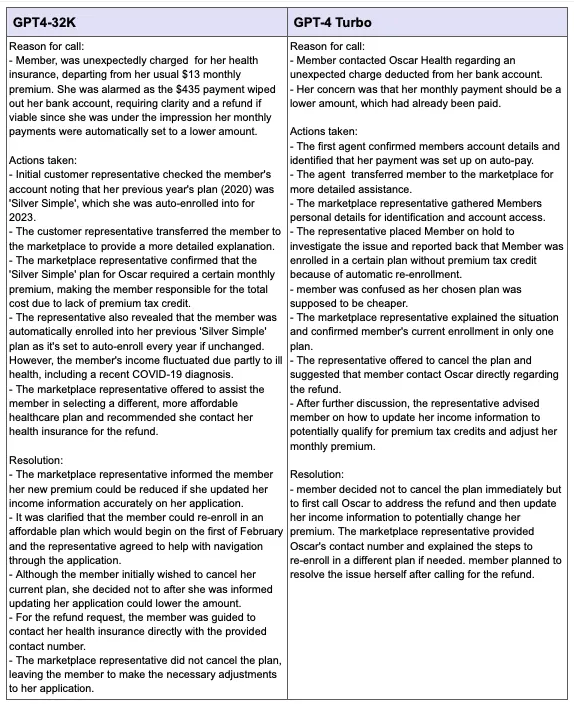
Call Summaries
Additionally, we passed phone transcripts to GPT-4 Turbo to compare with GPT4–32K. We can see that both summaries are thorough and detailed, containing specific details such as the cost of charges and type of plan the member was enrolled in.
We graded each response on a scale from 0–4 for correctness, comprehensiveness and readability. Each metric had a grading rubric that defined what merits a 0 and what merits a 4. We then took the average score across all responses generated.
Correctness: Is the response semantically the same as the expected response? Is it missing any critical aspects?
Score 0: the LLM response is completely incorrect, is completely contradictory to the expected response
Score 2: the LLM response is mostly the same as the expected response but is missing one critical aspect.
Score 4: the LLM response is semantically the same as the expected response and not missing any major aspect.
Comprehensiveness: How comprehensive is the LLM response compared to the expected response? Does it fully contain all aspects and details of the expected response?
Readability: How readable is the LLM response? Does it have redundant, incomplete or irrelevant information that hurts the readability?
For Medical Records Parsing and Clinical Form Structuring, we looked at the percentage of ICD-10 and CPT codes that were correctly extracted in the corrected response to determine the accuracy, which was then averaged across all responses.

Overall, we found GPT4-Turbo’s performance was on par with older models, it is cheaper, and we are able to leverage longer context window — which aligned with what Open AI announced:
We saw our scores for correctness of call summaries increase from an average of 3 out of 4 to 3.08 out of 4. Our accuracy rates for extraction increased for Clinical Forms compared to GPT4–32K and decreased slightly for Medical Records.
GPT-4 Turbo is able to infer ICD-10 codes from their description in medical records for ICD-10 extraction.
The new JSON response_format allows us to more consistently retrieve properly formatted JSONs for our extraction use cases.
The biggest unlock this new model brings is the ability to execute ICD-10 Extraction on longer documents. We now have a model that is cheaper and can handle longer medical records and documents, which decreases the number of calls we would need to make to OpenAI for a single medical record.