
Rating Member Services Interactions With LLMs
In our member services operations, we ask members to rate their interactions with us on member satisfaction (MSAT, general satisfaction with Oscar) and agent satisfaction (ASAT, their satisfaction with the care guide who helped them). How good is GPT-4 at estimating those two ratings from member services transcripts?
To test this, we pulled transcripts for each combination of MSAT and ASAT, which both go from 1 (bad) to 5 (great).
The prompt: “ You are to evaluate the quality of a conversation between a member of a health insurance company and the insurer's customer service agent. You will have transcript of the conversation. After the call ended, members are asked to evaluate how satisfied they were with the agent on the call (agent satisfaction, or ASAT), and they are asked how satisfied they were with their general experience with the health insurer (member satisfaction, or MSAT). Members can rate both satisfaction scores, ASAT and MSAT, on a scale of 1 to 5. A rating of 1 means the member is extremely dissatisified, and a rating of 5 means the member is fully satisfied with the agent (ASAT) or insurer (MSAT). Your task is to guess, from reading the transcript, how the member would likely have rated ASAT and MSAT. State your guess for ASAT and MSAT, and describe for each why you guessed the way you did. “
This is zero-shot learning, and the results aren’t particularly impressive. Because MSAT and ASAT can differ, we need to collapse them into one metric on the x-axis, so here we average them:

Here we just look at those calls where MSAT and ASAT are the same:

MSAT seems easier to measure than ASAT, it has slightly more variation in the chart above. But generally, GPT stays way too close to the middle of the range, and gets both bad and good calls wrong.
Now let’s try to move this more towards extracting meaning and drivers of satisfaction.
The prompt: “
A health insurer records and transcribes all conversations between the insurer's customer service agents and the insurer's members. After each conversation, the member is asked to respond to a survey that evaluates their satisfaction as a member. The member rates how satisfied they were with the agent on the call (agent satisfaction, or ASAT), and they rate how satisfied they are with their general experience with the health insurer (member satisfaction, or MSAT). Members can rate both satisfaction scores, ASAT and MSAT, on a scale of 1 to 5. A rating of 1 means the member is very dissatisfied with the agent (ASAT) or insurer (MSAT), and a rating of 5 means the member is very satisfied with the agent (ASAT) or insurer (MSAT). Below, you will see the transcript of such a conversation, and how the member rated MSAT and ASAT after the conversation. You are the most competent supervisor of the health insurer's customer service agents and have deep empathy for members dealing with the complicated U.S. healthcare system. You are the best at helping your customer service agents understand in detail how they can do a better job to lift the satisfaction of their members. For that reason, you are to identify the reasons why the customer in this transcribed conversation rated ASAT and MSAT the way they did, so you can help other customer service agents do the best imaginable job in the future and make their members happy. For ASAT, list up to 3 reasons why the conversation made the member rate the ASAT in the way they did. Describe each reason in sufficient detail for future education of customer service agents. Include the evidence or clue from the call transcript that made you pick the reason. If the ASAT is bad, find reasons why it is so bad; if it is good, find reasons why it is good. If it is balanced, find both. For each reason, estimate the impact that this reason alone would have had on the member's ASAT rating: -- for very negative, - for negative, +- for neutral, + for positive, ++ for very positive. For MSAT, list up to 3 reasons why the member rated his general satisfaction with the insurer in the way they did. Describe each reason in sufficient detail for future education of customer service agents. Number each reason by 1 to 3 (or fewer). Include the evidence or clue from the call transcript that made you pick the reason. If the MSAT is bad, find reasons why it is so bad; if it is good, find reasons why it is good. If it is balanced, find both. For each reason, estimate the impact that this reason alone would have had on the member's MSAT rating: -- for very negative, - for negative, +- for neutral, + for positive, ++ for very positive. Output your data in the following format of the example below:
ASAT Driver 1 Description = The agent was patient and polite.
ASAT Driver 1 Impact = ++
ASAT Driver 1 Evidence = When the member got upset that the insurer would not cover the cost of the surgery, the agent very calmly described how the member can appeal the decision by filing a case. The member evidently calmed down after the agent’s thoughtful discussion.
ASAT Driver 2 Description = The agent solved the member’s problem without further delay.
ASAT Driver 2 Impact = ++
ASAT Driver 2 Evidence = The agent was able to authorize the member’s drug reimbursement on the call. He did not want to make the member call a different phone number. Instead, he went to great lengths to solve the issue directly.
ASAT Driver 3 Description = The agent lacked confidence in some of the information he gave.
ASAT Driver 3 Impact = -
ASAT Driver 3 Evidence = When the member asked about whether podiatry is included in his plan benefits, the agent stammered and was not sure that would be the case. Even after consulting documents, he did not give a clear answer.
MSAT Driver 1 Description = The member was unable to find in-network cardiologists close to his home.
MSAT Driver 1 Impact = -
MSAT Driver 1 Evidence = The member stated that the closest cardiologist available was 20 miles away from where he lives. He was unable to find any other cardiologist in the insurer’s network closer to his home.
MSAT Driver 2 Description = The member received an unexpected bill from a doctor.
MSAT Driver 2 Impact = --
MSAT Driver 2 Evidence = The member received a bill from a recent primary care physician visit. He thought that the short surgery the doctor performed in his office would be covered by his plan. But the charge was denied by the insurer, and the member received the unexpected bill.
MSAT Driver 3 Description = The member was treated rudely by a physician recommended by the insurer.
MSAT Driver 3 Impact = --
MSAT Driver 3 Evidence = The member found a new dermatologist through the insurer’s website. When he visited the doctor, the doctor yelled at the member for coming to his office too early, and the member was put off by that and felt treated poorly. Since the insurer recommended the doctor, the member is angry at the insurer.
Here is the transcript:
“
Observation: Extracting drivers from text that correlate with actual ratings works quite well.
Let’s look at what it derives from this. It actually makes sense: the relationship between actual MSAT or ASAT and how many positive or negative drivers are present is pretty tight.

Some interesting results highlighted in yellow:
Only 23% of ratings in MSAT = 5 are ++, but 80% of ratings in ASAT are - in other words, it is harder to find clearly good drivers for high MSAT.
For ASAT = 2, there are more positive drivers than for MSAT = 2 - in other words, low ASAT is harder to describe through drivers.
For MSAT = 3, 59% of drivers are -, but for ASAT = 3, only 36% are - in other words, even when members are disappointed on the call, they might still have reasonable MSAT, or it is harder to bring down their member satisfaction.
But generally, low MSAT and ASAT (1 and 2) are very explainable through drivers: 80% of drivers are bad.
What this also means: these drivers are valid - their appearance correlates well with the ultimate ASAT/MSAT, and we can use them.
But we have too many drivers now, and many of them are redundant or only slight variations of others. So we use GPT-4 to aggregate them. That’s for another write-up.
Now we feed the list of those satisfaction drivers from above into the prompt.
The prompt: “
You are the leader of the customer service operation for a health insurer. Below is a list of drivers for member satisfaction of the insurer. You previously identified these drivers in transcripts from member services calls. Each driver has three parts of information: an index, a description of why this driver makes a member happy or unhappy, and a rating of the driver’s impact on the member’s satisfaction. The impact on member satisfaction is rated as follows: -- for very negative, - for somewhat negative, +- for neutral, + for somewhat positive, ++ for very positive. For example, the driver (0, --, Policy not active despite premium payments) indicates that if a member’s insurance policy is not active despite the member having paid monthly premiums, it makes the member very dissatisfied.
After a phone call with member services, the member is able to rate his or her satisfaction with the health insurer. Members can rate their member satisfaction, MSAT, on a scale of 1 to 5. A rating of 1 means the member is very dissatisfied with the insurer, and a rating of 5 means the member is very satisfied with the insurer.
Your job is to estimate the member’s satisfaction with the insurer, based on the transcript. First, use the list of satisfaction drivers below to identify which drivers appear in the transcript. Second, use the drivers’ impact on satisfaction to conclude how satisfied or dissatisfied the member was, and how he or she would have rated their MSAT on a scale of 1 to 5.
Here are the drivers:
(0, --, Policy not active despite premium payments)
(1, --, Lack of clear communication during enrollment)
(2, --, Inability to provide immediate coverage for a current hospitalization)
(3, --, Denial of medication)
(4, --, Slow prior authorization process)
[abbreviated]
Now list the drivers that are present in the following transcript. Only list those drivers that have to do with the member's satisfaction with the insurer, do not list any drivers of how the agent influenced the member on the call. Based on only the fundamental satisfaction drivers, estimate the member satisfaction on a scale of 1 to 5.
The output format is as follows:
List of drivers
MSAT estimate = [your estimate].
“
This is what we get:
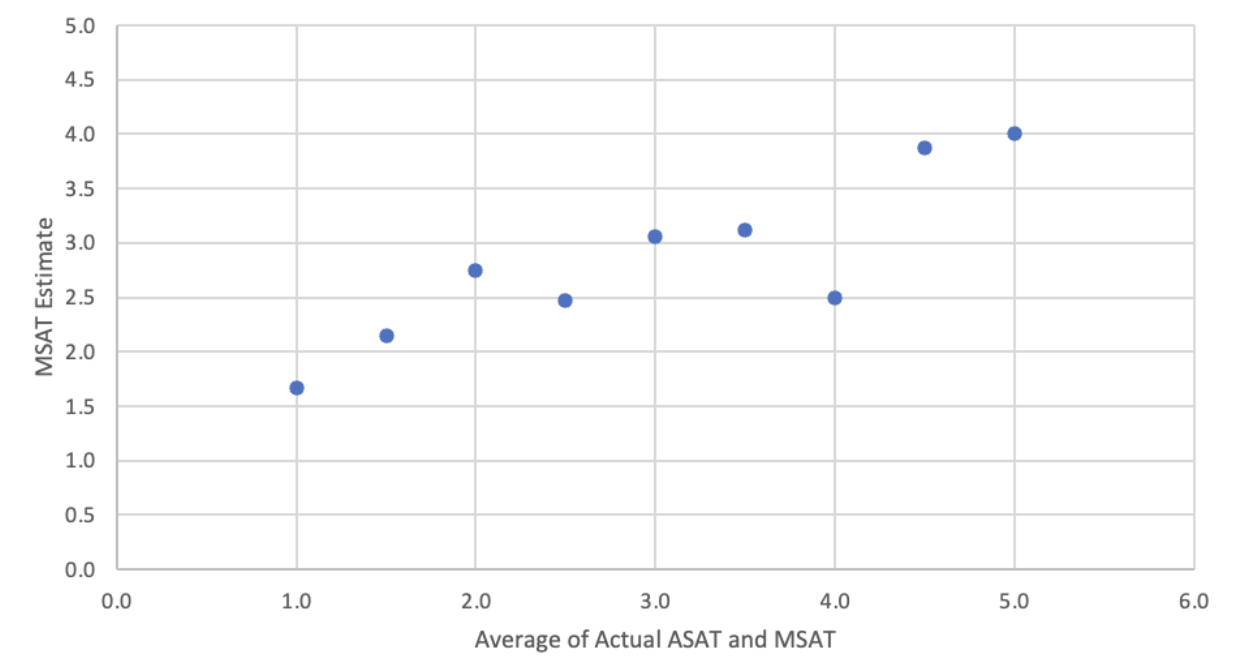

The second methodology works way better: for both bad and good calls, we get GPT-4 to estimate MSAT much more tightly if we provide the previously extracted member satisfaction drivers.
(What we did here is effectively follow an indirect “chain-of-thought” strategy: GPT-4 can’t backtrack, and it has limited circuit depth, so it isn’t able to both form driver reasons and then use them to rate calls all in one go - but by producing intermediate output, aka the satisfaction drivers, it is able to complete the logic chain end-to-end.)
Here is the methodology flow chart:
Pull N member services transcripts for each combination of MSAT and ASAT, so 5 x 5 x N transcripts in total. Each transcript will very likely be less than 20K tokens or so. If not, cut them off or discard them.
Feed each transcript plus actual MSAT and ASAT into GPT-4. Ask it to identify up to 3 reasons that explain the MSAT and ASAT from the call transcript only, and to cite the evidence in the transcript that supports each reason, and to flag each reason with whether it was very negative/positive or slightly negative/positive.
The full list of reasons (separately for MSAT and ASAT) from all calls should be around N x 5 x 5 x 3. It will contain lots of redundancies, because we ran each transcript individually without aggregating any of the drivers/reasons. But now take that full list and ask GPT-4 to rate each call by identifying reasons from the list, and aggregating their impact.