
A Simple Example for Limits on LLM Prompting Complexity
By Mario Schlosser, Co-Founder and Chief Technology Officer at Oscar
LLMs are capable of spectacular feats, and they are also capable of spectacularly random flame-outs. A big systems engineering issue remains figuring out how to tell one from the other. Here is an example for the latter.
It is well-known that LLM performance is very sensitive to prompt formulation. In some cases, that makes “algorithmic sense,” like when prompting an LLM to operate in chain-of-thought (“think through this step by step”): that effectively makes the LLM use its own output as short-term memory, which means you’re effectively chaining many LLMs together. In other cases, it doesn’t make any algorithmic sense, but human intuition helps realize why a particular prompt works: for example, prompting the LLM to “take a deep breath” apparently increases performance by a little. In this example, there is perhaps enough pattern matching in the pre-training data that this is associated with better performance, so it biases the LLM output towards that better performance. But in other cases, prompt complexity can be odd and hard to quantitatively assess upfront. Here is a really simple example.
We came across this when asking the LLM to a) categorize many comments from members by topical area and b) show which comment belongs to which categories, in one go. That seemingly simple prompt fails in hard to predict ways. So we tried to create a cleaner experiment. The experiment is as follows: we created a list of 280 objects that have a definitive color, which should be clear and obvious in the LLM’s pre-training data. For example, an arctic hare is white, a domino is black, a cauliflower is white, a radish is red, spinach is green, grass is green etc.
We then gave GPT-4 an increasing list of these objects and asked it to mark up the list of objects with their most likely color. Here is the prompt:
You are a bot who is helping organize objects by colors.
Classify the objects below into colors.
The following gives an example for input and output format. Follow the output format strictly.
The output must only consist of an object name, followed by a comma and space, followed by the color of the object, in each row.
If you receive the following input:
1. sewing machine
2. arctic hare
3. domino
4. life jacket
5. blackberry
6. plastic fork
7. post-it note
8. daffodil
9. cauliflower
10. cranberry
11. jaguar
12. picnic table
13. snowy owl
Then you produce the following output:
sewing machine, white
arctic hare, white
domino, black
life jacket, orange
blackberry, black
plastic fork, white
post-it note, yellow
daffodil, yellow
cauliflower, white
cranberry, red
jaguar, black
picnic table, brown
snowy owl, white
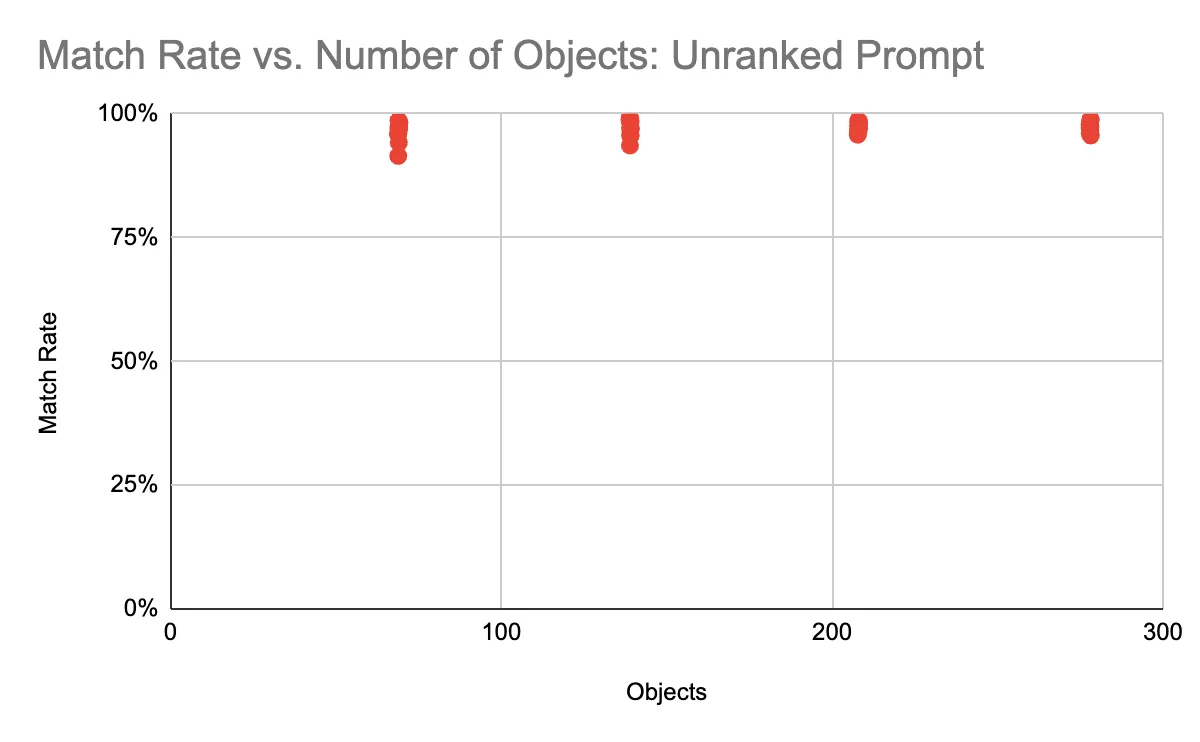
The chart below shows the percent of objects for which GPT-4 correctly identified the color, with temperature = 0 (i.e., no implied randomness), by the number of objects in the context window. (Testing 69, 139, 208 and 278 objects at once, respectively.) This is impressive performance, given that even humans might not always classify a picnic basket as brown (one of the objects in the list). By the way, it is odd that even with temperature = 0 there is some randomness in the output. That will become important later.
But now we do something supposedly extremely simple. We ask GPT-4 in the same prompt to not only mark up each object with its color, but in its output to also group the objects by color, and to rank the group of objects by the frequency of occurrence of the color. So if a list of 20 objects has 10 white objects and 5 black objects, then first list all the white objects, then all the black objects, and so on. Here is the prompt:
You are a bot who is helping organize objects by colors.
Classify the objects below into colors.
Then rank the colors in order of frequency: list all objects of the most frequently occurring color first, then all objects of the next-most frequently occurring color, and so on.
The following gives an example for input and output format. Follow the output format strictly.
The output must only consist of an object name, followed by a comma and space, followed by the color of the object, in each row.
All objects of the same color must be listed together, and the colors must be listed in order of frequency, with the most frequent color first.
If you receive the following input:
1. sewing machine
2. arctic hare
3. domino
4. life jacket
5. blackberry
6. plastic fork
7. post-it note
8. daffodil
9. cauliflower
10. cranberry
11. jaguar
12. picnic table
13. snowy owl
Then you produce the following output:
sewing machine, white
arctic hare, white
plastic fork, white
cauliflower, white
snowy owl, white
domino, black
blackberry, black
jaguar, black
post-it note, yellow
daffodil, yellow
life jacket, orange
cranberry, red
picnic table, brown
This prompt “breaks” the LLM. The added complexity of having to generate the color for each object, then group, then rank, seems to be too much. First, we observe that virtually none of the outputs ever get the ranking entirely right: while the color groups with the most objects tend to be listed first in the output, it is more of a loose correlation than a definitive numerical ranking.
Second, the new complexity of the prompt obliterates GPT-4’s ability to accurately do the color classification well. In other words, even though the task of classifying colors is clearly a subset of the overall task, this minor underlying task suddenly gets much worse. Here is the chart of the percent of objects where GPT-4 gets the color right.

This is an unexpected outcome. Here is a task that GPT-4 clearly does very well — identifying colors. But it gets completely overshadowed by the fact that it now also has to handle other tasks.
The other weird thing here is the apparent randomness. Again, we’re running this with temperature = 0, which supposedly means that stable input yields stable output. And notice too that each dot (each test run) just randomly selects x objects from the 278 we have in total. (In fact, the last test run just uses all 278, in random order.) None of that should have any impact on the outcome. But in fact it has huge implications, as you see in the chart above.
Let’s take one look at a particularly strange example. Note that for each test run, we randomize the objects only once, at the very beginning. Then we just take the first 69 and run them through, then the first 139, and so on. What’s strange about this run is that the LLM starts hallucinating in the (entirely independent!) test run with 139 and 208 objects; but when we take the exact same order of objects and expand to the full 278, it suddenly gets it right again. (The hallucinations each time are of the form that it just starts repeating the same object over and over, or the same color — it’s like it gets stuck in some token production loop.)
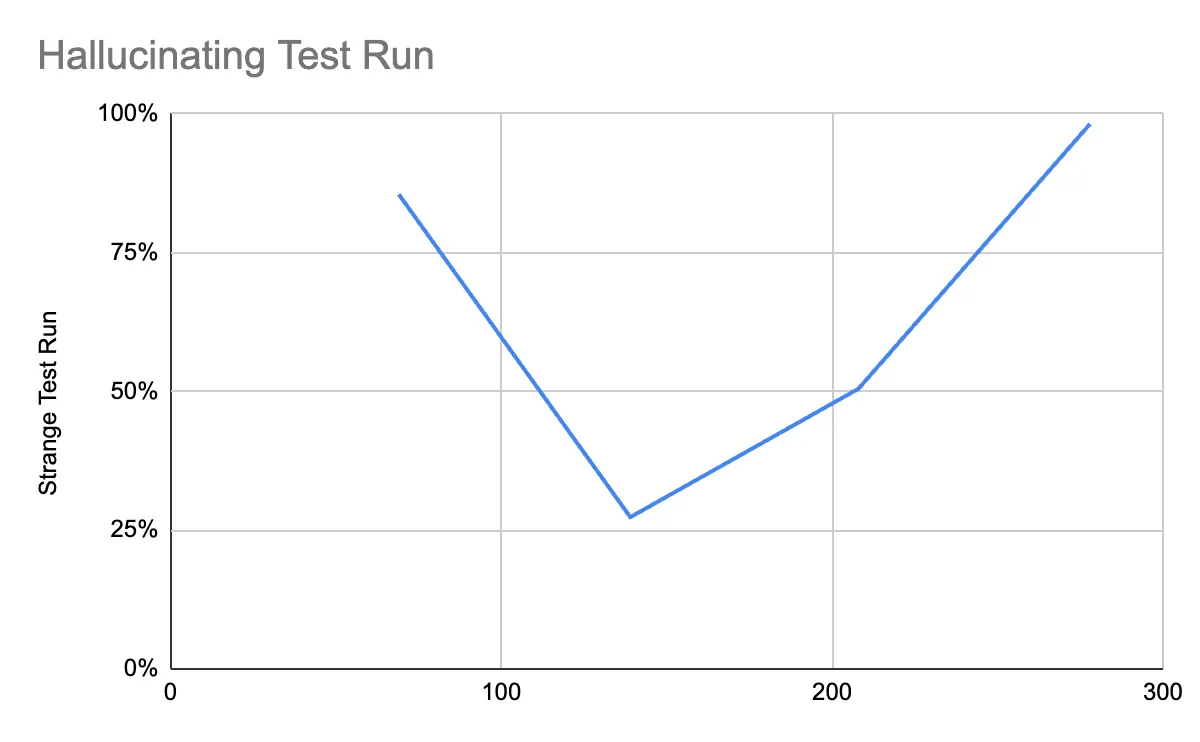
What is the conclusion here? First of all (but we already know this), temperature = 0 does not mean no randomness. Somewhere in this process, the LLM always picks up randomness (actual physical differences in the GPU?). Second, we ought to have some metric that quantifies “prompt complexity”: when a prompt goes above a certain threshold of complexity, very random things can start to happen. Here, the LLM feels human yet again: remember when you played the Simon lights-and-sounds memory game and get to higher numbers? Usually you don’t just make one mistake once your short-term memory gets overloaded, you just forget the entire sequence. It seems like GPT-4 picked up that habit from us humans, too.